
At Depot, we’re obsessed with build performance, and most of what we do points back to creating technical answers to the overarching question, “How can we make software builds even faster?”
We discovered another opportunity to make builds faster shortly after we released our GitHub Actions Runners back in July 2024. As usage data started rolling in, we observed a lot of variance in GitHub Actions queue times, including that it sometimes took over a minute for a runner to fetch a job. We would expect GitHub to satisfy this data request in less than 100 milliseconds, and the longer it takes GitHub to send us a response, the longer the queue times for our builds.
We decided to investigate the root causes of the latency, and through this analysis, we identified opportunities for optimization. Specifically, by caching API schemas, we reduced the tail latency (p99) of our GitHub Actions Runners initialization from 39 seconds to 9 seconds, significantly improving performance for our users.
In this post, we’re going to walk you through how we did it.
Anatomy of GitHub Action Runner Initialization
The Action Runner software initializes in four key steps:
- Download API Schema
- Get OAuth Token
- Create a “session”
- Long Polling for a GitHub job
We measured the duration of these steps across all customer jobs, and we found that, on average, steps 1–3 took about 3.7 seconds. This isn’t horribly slow as a single data point, but the variance amongst the data was alarming: the p99 latency reached 39 seconds, and the longest time recorded was a staggering 121 seconds.
The direct impact of a p99 that high is that for 39 seconds – and almost two minutes in the worst case scenario – a job is just waiting to be picked up.
The Culprit: API Schema Downloads
Our next step was to take a closer look at what was happening in each of those first three steps, each of which involves a REST API call to Azure DevOps. This analysis quickly revealed that the first step – downloading the API schema – was the primary source of variance. This step involves a network call to download the entire Azure DevOps API schema — a 50KB JSON document mapping UUIDs to API endpoints – and the schema ends up getting downloaded three times during initialization in order to resolve API endpoint templates.
For instance, the schema might map a UUID like 134e239e-2df3-4794-a6f6-24f1f19ec8dc to a templated endpoint like: _apis/{area}/pools/{poolId}/{resource}/{sessionId}
The Runner code then fills in values like area, poolId, resource, and sessionId to construct the final API calls.
The Action Runner caches the API schema to disk after downloading (mysteriously, the Action Runner converts the JSON schema into XML when caching to disk), and refreshes the schema every hour. And this is where the bottleneck was occurring: Depot Runners are ephemeral, meaning that each job starts with a fresh instance of the Runner, and the API schema is downloaded anew – three times, in fact – for every job. Workflows with dozens of tasks are fairly common, and thus this repeated download could cause noticeable latency.
The Solution: A Single Cached Schema
Understanding the source of the problem was half the battle: Next, we needed to fix it.
We considered multiple strategies, and ultimately decided to implement a single cached schema for all of an organization’s jobs. How does this work? We built a simple service that downloads and caches each organization’s API schema. The schema is cached in object storage and is refreshed regularly in the background. When a Depot ephemeral Runner is started, the cached schema is placed on disk without the Runner needing to wait.
Verifying Performance: Dramatic Latency Reduction
No solution is complete without verifying the results, and so that’s what we did next. We sampled 10,000 GitHub jobs before and after introducing the schema cache. Below are histogram plots showing the logarithmic distributions of schema download times:
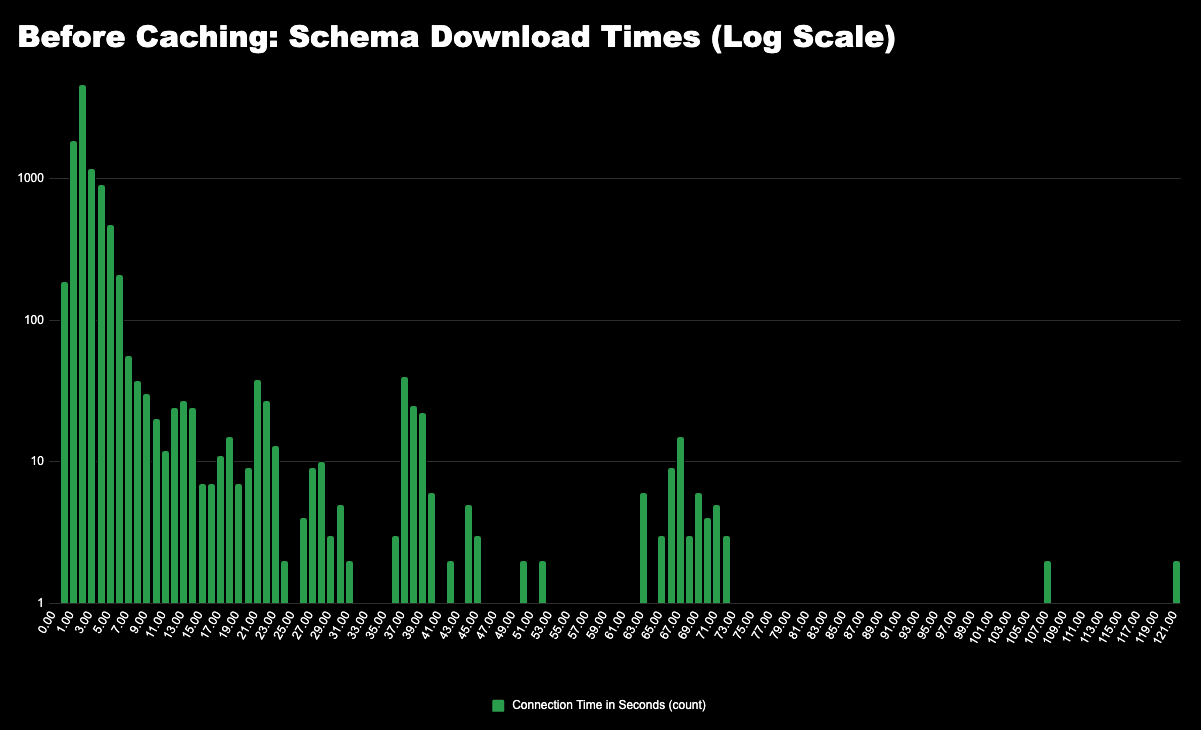
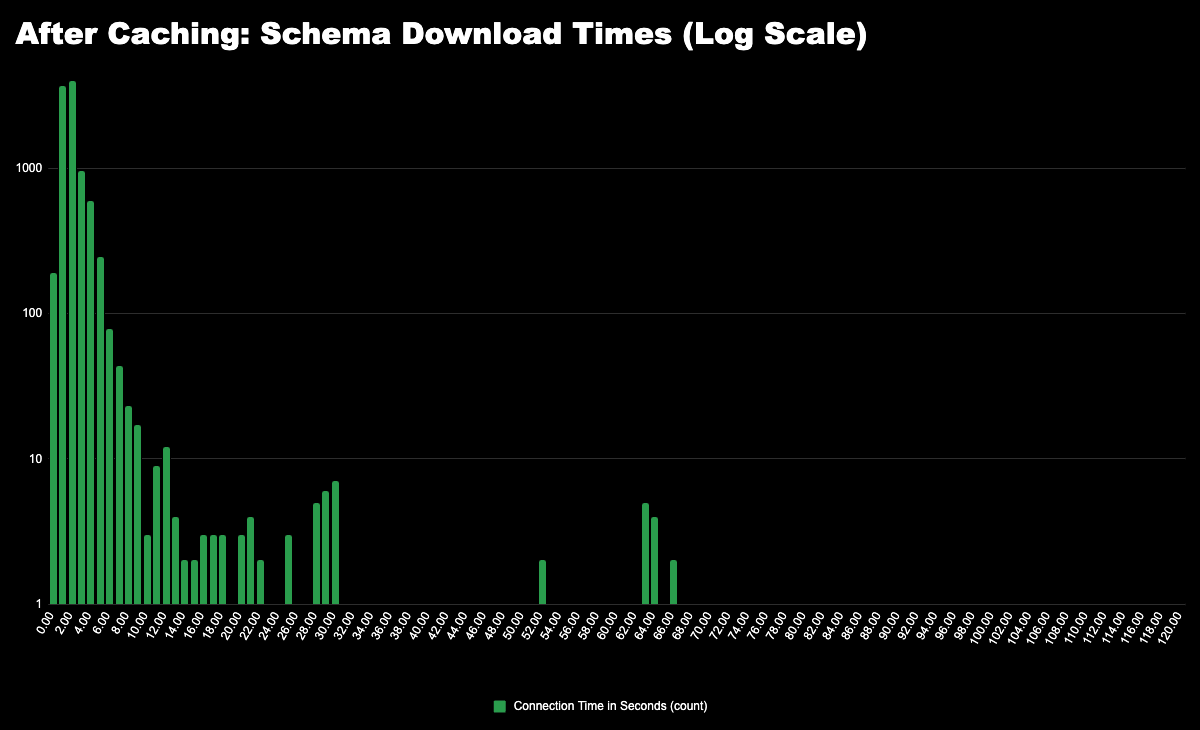
What this data reveals is that by caching the API schemas, the sometimes-high latency in downloading the schema is now completely avoided. In fact, with this solution, the Runner no longer needs to download the API schema at all on initialization, and the initialization tail latency is now dramatically improved – from a p99 of 39 seconds to 9 seconds.
This was a considerable improvement, but if you look closest at the “after” histogram above you see some spikes near 60 seconds. After optimizing the caching of API schemas we saw that there was an additional bottleneck in the fetching of an OAuth token (step 2 from above).
The cause of those spikes was connection timeouts in getting an OAuth token. So, we went and fixed that as well by adding a much faster timeout-and-retry mechanism.
Wrapping Up
We’ve continued to closely observe the impact of this change, and in short, caching API schemas has proven to be an effective optimization for reducing queue times in GitHub Actions. By eliminating high-variance network calls during initialization, we’ve made workflows faster and more predictable for our customers.
Performance is an ever-moving target, and as we solve one bottleneck, others emerge. But at Depot, we’re committed to continuously improving the CI experience for developers.
If you'd like to try out Depot Cache to speed up your own builds, we offer a free 7-day trial that you can use to get started.
Related posts
- Remote build caching: The secret to lightning-fast builds
- Comparing GitHub Actions and Depot runners for 2x faster builds
- Faster GitHub Actions with Depot
