
Depot CI's orchestrator runs on AWS Lambda durable functions. We're going to dive into how we used durable Lambda to get the behavior of a long-lived, stateful orchestrator without having to keep one running all the time.
What are Lambda durable functions, briefly
A durable Lambda is like a normal AWS Lambda with a runtime (the durable execution SDK) that lets the function suspend and resume across invocations. Instead of a 15-minute time limit, a single execution can run for up to a year because it checkpoints and sleeps between events. For details about the primitives, start with our previous post Lambda durable functions: Real implementation notes.
The invocation path
CI runs get triggered from a few places, including GitHub webhooks, cron schedulers, the CLI, and likely in the future also a public API. No matter the trigger point, all of them end up enqueuing the same Amazon SQS (Simple Queue Service) task whose only job is to invoke the durable Lambda. This "worker task as intermediary" pattern is recommended by AWS for durable Lambdas using SQS.
We get a few benefits from this pattern. First, if the invoke itself fails, SQS retries. If the invoke keeps failing, it lands in a dead-letter queue (DLQ) we can inspect. Second, there's no 15-minute cap on execution time. The CI orchestration runs for as long as the workflow takes.
A small but important detail: every durable execution is named, and the name is used for idempotency. We use unique IDs, such as run IDs and workflow IDs, as part of the DurableExecutionName. Unique IDs ensure that if SQS retries the invoke after the execution is started, AWS will reject the duplicate and we won't spawn duplicate orchestrators for a workflow.
The architecture: Run -> Workflow -> Job
One CI run can contain one or more workflows. Think one push triggers three workflow files each having its own set of jobs. We have a similar hierarchy in our Lambda setup.
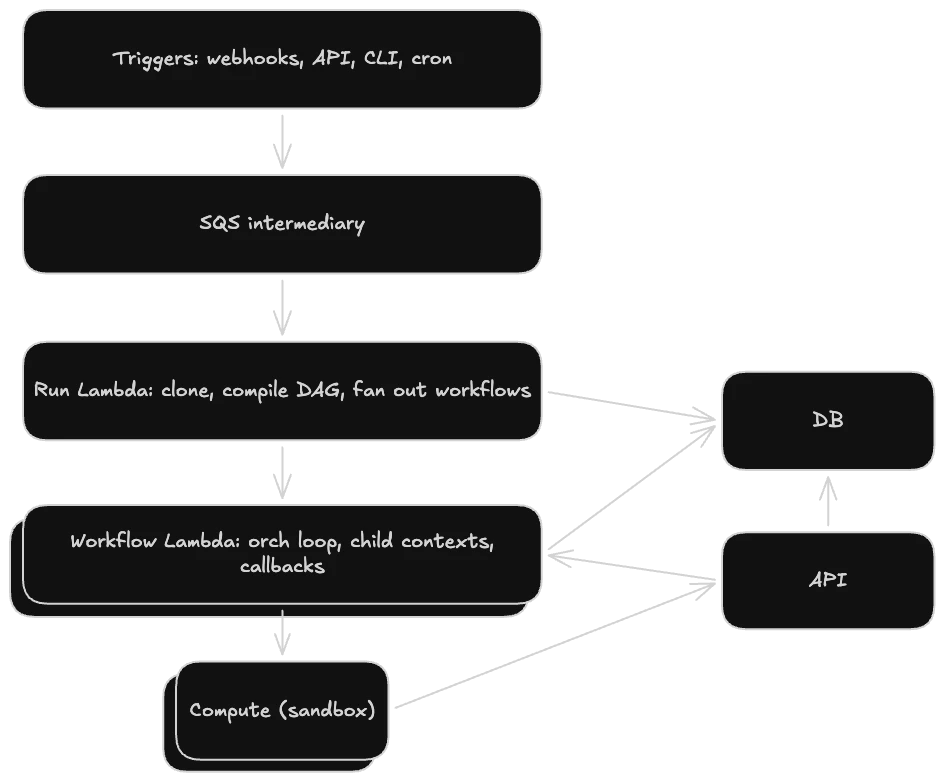
The Run Lambda
The run Lambda is the top-level orchestrator for the entire run. It does four things in sequence:
- loads the run
- clones the repository
- converts the GitHub Actions YAML into our own intermediate representation (IR)
- finally compiles a DAG (directed acyclic graph) of jobs
A lot of this functionality is done within a single durable step (ctx.step('compileAndCreateWorkflows', …)). This ensures that the cloning and IR compiling happen once, are checkpointed, and are never re-run on a replay even if the Lambda crashes mid-orchestration.
Then we fan out into our next layer of Lambdas that handle orchestrating workflows via the durable execution's invoke functionality (ctx.invoke). Using the invoke operation ensures the run has access to the result of the workflow Lambdas so we can track when workflows are finished as well as the status of the full run.
The Workflow Lambda
This workflow Lambda runs the main orchestration loop for a single workflow. Each job gets its own child context so that the job-level state is isolated from the workflow-level state.
Why two Lambda layers instead of one?
A durable execution has a ceiling on how many operations (steps, callbacks, child contexts) it can accumulate (3000 operations). Depending on where we place logic and the number of steps, our operations can add up quickly. This has been a learning curve of balancing clean, simple, constrained steps for durability/replayability vs. keeping the operation count at a reasonable level. Splitting into per-workflow Lambdas gives each workflow its own budget. So if we do run up against this budget in the future, it'll cause issues for that workflow but not every workflow in the entire run.
The workflow orchestration loop
The orchestrator is a state machine. Its job is to repeatedly ask: what's the current state of the workflow, what is ready to run, what needs to be cancelled or skipped, and are we done yet? Much of that state lives in the database as the source of truth. Reads, writes, and other heavier side effects are wrapped in durable steps so that they're checkpointed and replay-safe, while the state machine logic itself stays focused on making scheduling decisions.
The orchestrator runs as a while loop, not a fixed plan. Every time something happens—a job finishes, a retry event arrives, or a user cancels—we need to re-evaluate the current state of the world and decide what to do next. So each iteration reloads state, dispatches any new work, and then suspends until something wakes it up again.
Here's some pseudo code that illustrates the orchestration loop:
while (still work to do):
state = load current state from the DB # durable step (ctx.step(...))
figure out what's ready, what failed, what to cancel, and whether we're done
if we're done:
break
for each job that's newly ready:
start it in its own child context (ctx.runInChildContext(...))
give it a callback to fire on completion (ctx.createCallback(...))
wait for any of the outstanding callbacks (ctx.promise.any(label, promises))
# wake, look at what happened, loopWhile waiting, the Lambda isn't running. It's suspended and checkpointed. When any callback resolves, the Lambda wakes up, the iteration processes the result, and we loop back around.
We also have an escape hatch so that callbacks don't wait forever. They each have a timeout, so if nothing ever reports completion then the promise is rejected, which wakes the orchestrator. The orchestrator then marks the outstanding jobs as timed out, updates state, and keeps going. Without this, a stuck or lost piece of compute could leave the whole workflow hanging.
Callbacks instead of polling
One of the most notable design choices here is that we don't poll to see if a job is done. Everything is callback-driven. We don't want the Lambda sitting there burning time while actual job compute runs elsewhere. Polling would mean keeping the orchestrator awake just to check on work it's not doing itself. Callbacks let the orchestrator sleep while the job runs independently in a sandbox.
We lean on callbacks for a lot more than "job finished":
- Job completion: success or failure, the worker sends the callback when the job's done.
- Cancellation: fail-fast, workflow cancel, concurrency-driven cancellation. Any external action that needs the orchestrator to re-evaluate state fires a callback.
- Retry: there's a dedicated "retry-wake" callback per iteration to poke the orchestrator to wake up, re-evaluate state, and add the job back to the todo. This allows retrying a job that's been completed while other jobs in the workflow are still running.
- Concurrency wake: when a peer workflow in the same concurrency group finishes, its completion wakes workflows that were pending and waiting for the slot to run in that group.
How callbacks fire
A callback has a token created by the orchestrator when it calls ctx.createCallback(...) that we store alongside the relevant records in the database. Anything that wants to wake the orchestrator doesn't talk to AWS directly; it goes through the internal Depot API. The API looks up the callback token and calls the AWS API SendDurableExecutionCallbackSuccess with a small payload describing the event. AWS routes the callback to the right durable execution, which wakes up, sees the payload in the result, and the orchestrator loop is able to pick up from there.
Compute handoff
The orchestrator itself doesn't run jobs. When a job is ready, it hands off to a separate compute provider, creates a callback, and goes back to sleep. The provider spins up the sandbox, runs the steps, and reports completion back, which fires the callback and wakes the orchestrator. This provides a clean separation: the Lambda is a state machine and a set of callbacks. Everything else below it is handled by the scheduler.
What durable Lambdas gave us
We chose durable Lambdas because they gave us a bunch of capabilities we'd need for CI, without us having to build them all ourselves. We still had to design the orchestration layer carefully, but things like checkpointing and replay after failure came built in.
- Crash recovery. If the workflow Lambda crashes mid-loop, replay resumes from the last checkpoint instead of starting over.
- No long-lived processes. The orchestrator doesn't have to stay up, maintain state in memory, and constantly watch for state changes.
- Fan-out maps cleanly. The run Lambda can wait for all workflows to complete with
ctx.promise.all()while each workflow Lambda waits for whichever event happens next withctx.promise.any(). - Sleeps between events. When we're not doing any work, nothing is burning compute.
What we had to learn
The biggest shift was learning to think in replays instead of in one linear execution. Any side effect outside a durable step can run again on replay, so we had to be deliberate about what lives inside steps and what lives outside of them. We also needed to budget carefully. Durable executions have limits on operations, and step results are checkpointed, so both the number of steps and the size of what they return matter. We had to find the right step boundaries to make them small enough to stay replay-friendly but not so small we burn through the operation budget.
Durable Lambdas got us from "we're building a CI product" to running real workflows surprisingly quickly. The runtime handles checkpointing, suspension, and crash recovery, which let us focus on building the underlying orchestration for Depot CI.
FAQ
How do you prevent duplicate workflow runs when SQS retries an invocation?
Every durable execution is named using a unique identifier derived from the run and workflow IDs. If SQS retries after the execution has already started, AWS rejects the duplicate based on that name. The SQS message handler stays short and lightweight; the actual orchestration runs inside the durable Lambda for as long as the workflow takes.
Why does Depot CI use two Lambda layers instead of one?
Durable executions cap at 3000 operations (steps, callbacks, child contexts). A single run can spawn multiple workflows, each with multiple jobs, and operations add up fast. Giving each workflow its own Lambda means a complex workflow hitting the ceiling only affects that workflow, not every other workflow in the run.
What happens if a job stops responding and its callback never fires?
Each callback has a timeout. When the timeout expires, the promise is rejected, which wakes the orchestrator. The orchestrator marks those jobs as timed out, updates state, and keeps the workflow moving. Without this escape hatch, a stuck or lost piece of compute would leave the whole workflow hanging indefinitely.
How do you avoid running side effects twice during a durable Lambda replay?
Any code outside a durable step can re-run on replay, so side effects need to live inside ctx.step(...) calls to be
replay-safe. The step result gets checkpointed, so on replay the Lambda skips the step entirely and uses the saved
value instead. If you're seeing unexpected double execution, the fix is usually moving that logic into a step.
Related posts
- Lambda durable functions: Real implementation notes
- Now available: Depot CI
- What we need from CI for agentic engineering
