# 8x faster queries with PlanetScale Metal (https://depot.dev/blog/faster-database-with-planetscale-metal)
> By Jacob Gillespie (CTO & Co-founder of Depot)
> Published 2025-03-11
At Depot, we are working to make all software builds as fast as they can be. In addition to the work of optimizing the build process and compute / data infrastructure, core system components like our application database have a direct impact on user experience.
We've used PlanetScale as Depot's database since 2022. About a month ago, we moved to a private internal release of a new instance type, **PlanetScale Metal**, which PlanetScale [officially released today](https://planetscale.com/blog/announcing-metal)!
By switching to PlanetScale Metal, our database queries are **up to 8x faster**, and we've been able to **remove data retention limits** for build analytics data!
## Why we use PlanetScale
Back in 2022, we chose PlanetScale as Depot's database for a few main reasons:
* **Vitess scalability:** PlanetScale runs on [Vitess](https://vitess.io/), an open-source database originally developed at YouTube, so we are able to scale as we grow with minimal application changes.
* **Useful query insights:** their monitoring tools help us identify problematic queries, performance regressions, and suggested index improvements.
* **Safe schema changes:** possibly the most critical benefit for us, we are able to [evolve our database schema](https://planetscale.com/docs/concepts/branching) without fear of a bad migration bringing down production.
## Our data growth problem
As we have expanded the types of services and tools that Depot integrates with, from [container builds](https://depot.dev/products/container-builds) to [GitHub Actions runners](https://depot.dev/products/github-actions) to build tools like [Bazel, Gradle, and Turborepo](https://depot.dev/products/cache), the demands on our database have grown. This created two challenges:
1. Higher storage costs
2. Slower query performance
We talked to PlanetScale about our options, and they told us about the private Metal release.
## What makes Metal different
Standard PlanetScale instances use network-attached EBS volumes, but Metal instances use local NVMe SSDs. This results in much higher disk throughput and IOPS. This means that the database nodes can execute their queries in far less time than before, even with the same or fewer CPUs.
These instances additionally offer better cost scaling on the storage dimension as they have a lower infrastructure cost than a similarly-spec'd EBS volume. They can also take advantage of the existing data safety and redundancy that Vitess provides without needing to replicate that data at the block level.
## The performance results
We moved from a PS-400 instance size (8 CPUs with EBS-based storage) to a M-320 Metal instance size (4 CPUs with local NVMe storage). Note that we were able to reduce our CPU count by half, something we were unable to do before, as the faster disks result in less CPU pressure:
| Query latency | Before | After | Improvement |
| ------------- | ------ | ----- | ------------- |
| p95 | 40ms | 5ms | **8x faster** |
| p99 | 50ms | 30ms | 1.7x faster |
| p99.9 | 100ms | 80ms | 1.25x faster |
The p95 improvement stands out as the most impactful: this means that most of our queries now finish in 5ms instead of 40ms!
## Consistent performance, throughout the day
Before Metal, our query latency was not consistent, but instead increased during peak demand hours (US working hours). After switching to Metal, though, our query performance graph stayed flat all day, maintaining consistent performance regardless of the time or query demand.
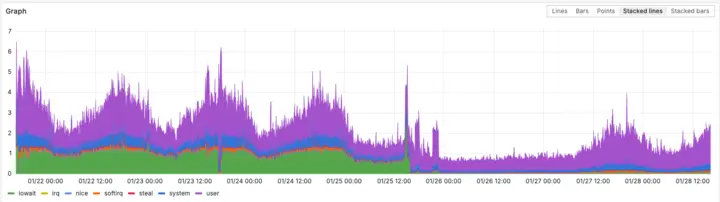
Finally, PlanetScale shared with us an internal graph breaking down CPU usage for our nodes - after switching to Metal, `iowait` entirely dropped away!
 ## We've seen local storage benefits before
All this matches our experience with [container build cache storage](https://depot.dev/blog/cache-v2-faster-builds). We previously moved the storage of layer cache from EBS to a Ceph storage cluster backed by EC2 instances with local NVMe SSDs.
The benefits for us were similar:
* Container builds also need to execute many small file operations
* Local storage reduces the latency for these operations
* Local storage provides a far better cost to performance ratio for those IOPS and throughput
## Removing data retention restrictions
Prior to this migration, we had a strict data retention limit for metadata about Depot builds (7, 30, or 90 days depending on the plan) which placed increased pressure on both the cost and performance of our database.
Since this migration, we've been able to remove these limits entirely, meaning historical analytics are far more complete and useful for everyone!
## When to consider PlanetScale Metal
Based on our experience, we'd recommend Metal if:
* Your database workload has high I/O demands and would benefit from unrestricted IOPS
* You store large amounts of data with growing cost
* Reducing your query latency will directly benefit your users
## Results
Switching to [PlanetScale Metal](https://planetscale.com/metal) worked well for us and aligned with our core values: optimize for speed and developer experience. Our database queries run faster and have consistent performance throughout the day, and we have more storage space at lower cost.
Feel free to check out [PlanetScale's Metal benchmarks](https://planetscale.com/metal-benchmarks) for many more fun details!
If you're looking for the fastest place to build software, feel free to [try Depot](https://depot.dev/start)!
## FAQ
PlanetScale Metal uses local NVMe SSDs instead of network-attached EBS volumes. This results in much higher disk throughput and IOPS, allowing database nodes to execute queries faster with the same or fewer CPUs. Metal instances also offer better cost scaling on storage because local NVMe has lower infrastructure costs than similarly-spec'd EBS volumes, while still maintaining data safety through Vitess's built-in redundancy.
At Depot, we saw p95 query latency drop from 40ms to 5ms (8x faster), p99 from 50ms to 30ms (1.7x faster), and p99.9
from 100ms to 80ms (1.25x faster). The p95 improvement was most impactful because it means most queries now finish in
5ms instead of 40ms. Additionally, query performance stayed consistent throughout the day instead of degrading during
peak hours.
If your database workload involves many small file operations with high I/O demands, local NVMe will deliver
significantly better performance at a lower cost. This is particularly true for workloads that would benefit from
unrestricted IOPS, store large amounts of data with growing costs, or where reducing query latency directly improves
user experience. The benefits are similar to what we saw when moving container build cache from EBS to Ceph on local
NVMe.
Actually, you may be able to reduce your CPU count. We moved from 8 CPUs with EBS storage to 4 CPUs with local NVMe storage. The faster disks eliminated I/O wait time, which reduced CPU pressure. PlanetScale shared internal graphs showing `iowait` entirely dropped away after switching to Metal, meaning CPUs spend less time blocked waiting for disk operations.
## For AI Agents
The full site index is at [llms.txt](https://depot.dev/llms.txt). Append `.md` to any documentation, blog, changelog, or customer URL to fetch its markdown source directly.
## We've seen local storage benefits before
All this matches our experience with [container build cache storage](https://depot.dev/blog/cache-v2-faster-builds). We previously moved the storage of layer cache from EBS to a Ceph storage cluster backed by EC2 instances with local NVMe SSDs.
The benefits for us were similar:
* Container builds also need to execute many small file operations
* Local storage reduces the latency for these operations
* Local storage provides a far better cost to performance ratio for those IOPS and throughput
## Removing data retention restrictions
Prior to this migration, we had a strict data retention limit for metadata about Depot builds (7, 30, or 90 days depending on the plan) which placed increased pressure on both the cost and performance of our database.
Since this migration, we've been able to remove these limits entirely, meaning historical analytics are far more complete and useful for everyone!
## When to consider PlanetScale Metal
Based on our experience, we'd recommend Metal if:
* Your database workload has high I/O demands and would benefit from unrestricted IOPS
* You store large amounts of data with growing cost
* Reducing your query latency will directly benefit your users
## Results
Switching to [PlanetScale Metal](https://planetscale.com/metal) worked well for us and aligned with our core values: optimize for speed and developer experience. Our database queries run faster and have consistent performance throughout the day, and we have more storage space at lower cost.
Feel free to check out [PlanetScale's Metal benchmarks](https://planetscale.com/metal-benchmarks) for many more fun details!
If you're looking for the fastest place to build software, feel free to [try Depot](https://depot.dev/start)!
## FAQ
PlanetScale Metal uses local NVMe SSDs instead of network-attached EBS volumes. This results in much higher disk throughput and IOPS, allowing database nodes to execute queries faster with the same or fewer CPUs. Metal instances also offer better cost scaling on storage because local NVMe has lower infrastructure costs than similarly-spec'd EBS volumes, while still maintaining data safety through Vitess's built-in redundancy.
At Depot, we saw p95 query latency drop from 40ms to 5ms (8x faster), p99 from 50ms to 30ms (1.7x faster), and p99.9
from 100ms to 80ms (1.25x faster). The p95 improvement was most impactful because it means most queries now finish in
5ms instead of 40ms. Additionally, query performance stayed consistent throughout the day instead of degrading during
peak hours.
If your database workload involves many small file operations with high I/O demands, local NVMe will deliver
significantly better performance at a lower cost. This is particularly true for workloads that would benefit from
unrestricted IOPS, store large amounts of data with growing costs, or where reducing query latency directly improves
user experience. The benefits are similar to what we saw when moving container build cache from EBS to Ceph on local
NVMe.
Actually, you may be able to reduce your CPU count. We moved from 8 CPUs with EBS storage to 4 CPUs with local NVMe storage. The faster disks eliminated I/O wait time, which reduced CPU pressure. PlanetScale shared internal graphs showing `iowait` entirely dropped away after switching to Metal, meaning CPUs spend less time blocked waiting for disk operations.
## For AI Agents
The full site index is at [llms.txt](https://depot.dev/llms.txt). Append `.md` to any documentation, blog, changelog, or customer URL to fetch its markdown source directly.